/ Долгопрудный
Новости
Эксклюзив
Видео
Выбрать город
О редакции
Вакансии
Контакты
Подписывайтесь
Выбор города
Введите название вашего города или выберите из списка:
Главная страница
Балашиха
Бронницы
Видное
Волоколамск
Воскресенск
Дзержинский
Дмитров
Долгопрудный
Домодедово
Дубна
Егорьевск
Жуковский
Зарайск
Звенигород
Истра
Кашира
Клин
Коломна
Королёв
Котельники
Красногорск
Краснознаменск
Лобня
Лосино-Петровский
Лотошино
Луховицы
Лыткарино
Люберцы
Можайск
Мытищи
Наро-Фоминск
Ногинск
Одинцово
Орехово-Зуево
Павловский Посад
Подольск
Протвино
Пушкино
Пущино
Раменское
Реутов
Руза
Сергиев Посад
Серебряные Пруды
Серпухов
Солнечногорск
Ступино
Талдом
Фрязино
Химки
Черноголовка
Чехов
Шатура
Шаховская
Щелково
Электросталь
Ваш город
?
Ваш город
?
Новости
Эксклюзив
Видео
Строительство
Культура
ЖКХ
Страна и регион
Еще
Строительство
Культура
ЖКХ
Страна и регион
Экология
Безопасность
Наш Физтех
Здоровье
Спорт
Общество
Новости
Дороги
Город
Новости Подмосковья
День Победы
Реклама
Образовательный кластер
Социальная сфера
Благоустройство
Образование
Транспорт
О редакции
Авторы
Рекламодателям
Контактная информация
Политика конфиденциальности
Подписывайтесь
Новости Долгопрудного
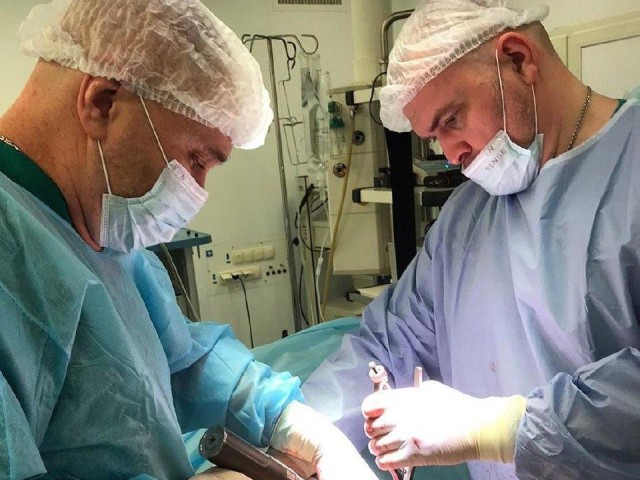
Врачи Долгопрудного используют уникальный эндопротез при хирургических операциях на тазобедренный сустав
Вчера в 17:45
В моем городе проблема!
Сообщить
В детской поликлинике приступил к работе новый врач уролог-андролог
Вчера в 12:31
В связи с ремонтом теплосетей в нескольких жилых домах отключат отопление и горячую воду
Вчера в 10:41
Ваше обращение принято.
Мы рассмотрим его в ближайшее время.
Закрыть
Опишите проблему
Добавить фото или видео
Тема:
Выберите тему
Дороги
ЖКХ
Благоустройство
Здравоохранение
Социальная сфера
Общественный транспорт
Строительство
Торговля
Мусор
Образование
Бизнес
Другое
Ваши данные:
Остаться инкогнито
Популярное
Образовательный кластер
Ребята из Физтех-колледжа представили уникальный 3D принтер на выставке «Россия» на ВДНХ
Вчера в 09:03
Социальная сфера
Педагог-психолог рассказала подросткам из приемных семей способы контроля негативных эмоций
Вчера в 10:53
Эксклюзив
Где готовят ароматный кофе в округе? Местами поделились жители
Вчера в 13:28
Эксклюзив
Поварами, пожарными и медиками стали на несколько минут школьники Долгопрудного
Вчера в 12:24
В моем городе проблема!
Сообщить
Цитаты
дня
Владислав Юдин
глава г.о. Долгопрудный
«С наступлением тепла будем активнее и шире проводить здесь тренировки на открытом воздухе, разноплановые культурные мероприятия»
Кирилл Чепурной
заведующий обсерваторией Технопарка Физтех-лицея
«Для Технопарка Физтех-лицея имени П.Л. Капицы мы получили зеркальный телескоп. Это дает возможность делать снимки, как объектов ближнего космоса, луны, солнца, планет солнечной системы, так и объектов космоса глубокого»
Новости
Благоустройство
Коммунальные службы выполняют уборку дорог и тротуаров на улицах Спортивная, Станционная, Магистральная
Вчера в 19:03
Новости
Штраф за шумную дискотеку выписали жительнице Долгопрудного
Вчера в 18:14
Главное за неделю
Здоровье
Врачи Долгопрудного восстановили функцию почек мужчине после сильнейшего отравления
16.04 12:53
Здоровье
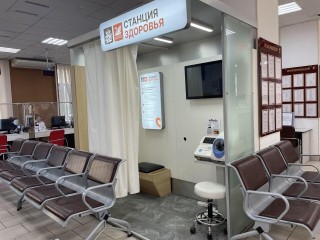
Провести экспресс-анализ ключевых показателей организма жители Долгопрудного могут в МФЦ
16.04 10:44
Благоустройство
В Центральном парке готовится к запуску новый фонтан
16.04 09:29
Культура
Золушки с принцами станцевали на костюмированном балу в Долгопрудном
15.04 19:06
Эксклюзив
ЖКХ
Стало известно, когда в Долгопрудном начнут отключать горячую воду
16.04 17:38
Общество
Медикаменты, одежду и продукты собрали неравнодушные жители округа для бойцов СВО
16.04 13:51
Город
Летчик-космонавт Юрий Батурин: «Мне Земля показалась очень большой»
12.04 18:22
Безопасность
Автоинспекторы рассказали слушателям автошкол, чем грозит непристегнутый ремень на экзамене и в жизни
12.04 15:00